Current Research Projects
Programmable Accelerator-Based Architectures
We are using a vertically integrated research methodology to investigate new programming frameworks, compilers, instruction sets, microarchitectures, and VLSI implementations for exploiting fine-grain parallelism using programmable accelerators. The software/hardware abstraction used in these new architectures is carefully designed such that the same binary can be executed on: traditional microarchitectures (e.g., simple in-order single-issue designs, complex out-of-order superscalar designs) with minimal performance impact; specialized microarchitectures to improve performance and/or energy efficiency; and potentially even adaptive microarchitectures that can seamlessly migrate applications between traditional and specialized execution to dynamically trade-off performance vs. energy efficiency. Our programming methodology and compiler work enables applications to be mapped to these new architectures with relatively little work, and our VLSI implementations using synthesis and place-and-route tools improve the credibility of our area, energy, and performance estimates. Our initial work explored such architectures within the context of exploiting diverse types of inter-iteration loop dependence patterns [MICRO'14]. More recently we have explored such architectures within the context of task-based parallel programming and work-stealing runtimes [MICRO'17].
General-Purpose Graphics Processing Unit Microarchitecture
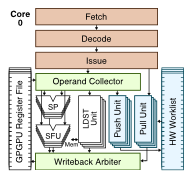
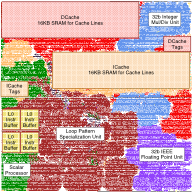
We are leveraging our expertise in designing data-parallel accelerators to explore microarchitectural techniques that can improve the performance and efficiency of GPGPUs. While GPGPUs have traditionally focused on exploiting control and memory-access structure, we have also been exploring a new kind of structure called value structure. Value structure occurs when multiple threads operate on values that can be compactly encoded, e.g., by using a simple function of the thread index. We proposed three microarchitectural mechanisms to exploit value structure based on compact affine execution of arithmetic, branch, and memory instructions [ISCA'13]. Our more recent work has explored how GPGPUs can efficiently execute irregular algorithms that read and modify graph-based data structures and dynamically generate additional parallelism using fine-grain hardware worklists [MICRO'14].
Algorithm and Data-Structure Hardware Specialization
Serious physical design issues are breaking down traditional abstractions in computer systems and motivating computer architects to turn to hardware specialization. Resolving the tension between less efficient general architectures and more efficient specialized architectures, particularly within the context of mainstream computing platforms, is one of the grand challenges facing the computer architecture community. We are exploring hardware specialization for a variety of different algorithms and data-structures. We are collaborating with Prof. Zhiru Zhang and his students to study techniques to improve the ability of high-level synthesis to automatically generate hardware for irregular applications. Our recent work explored improving high-level synthesis by decoupling algorithms from complex data structures [DAC'16] and augmenting traditional algorithms with support for dynamic hazard resolution [FPGA'17].
Architecture and Circuit Co-Design for Integrated Voltage Regulation
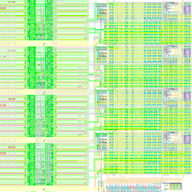
Recent work has shown that monolithic integration of voltage regulators will be feasible in the near future enabling reduced system cost and the potential for fine-grain voltage scaling (FGVS) in level (i.e., many different voltage levels), space (i.e., per-core regulation), and time (i.e., fast transition times between levels). More specifically, on-chip switched-capacitor regulators appear to offer an attractive trade-off in terms of integration complexity, power density, power efficiency, and response time. In this project, we are using architecture-level modeling to explore new online FGVS controllers that are able to improve performance and energy efficiency at the same power by exploiting fine-grain activity imbalance in multithreaded workloads. We are also collaborating with Prof. Alyssa Apsel and her students to use circuit-level modeling to explore various approaches to organizing on-chip voltage regulation to enable per-core FGVS at low area overhead. This collaboration has resulted in a new architecture/circuit co-design we are calling reconfigurable power distribution networks [MICRO'14]. Based on insights gained from these experiments, our research groups have jointly taped out a test chip in a TSMC 65nm process containing a new kind of integrated voltage regulator [TCASI'18]. We have also proposed asymmetry-aware work-stealing (AAWS) runtimes, which combine static asymmetry (e.g., different core microarchitectures), dynamic asymmetry (e.g., per- core dynamic voltage/frequency scaling), and work-stealing runtimes to improve the performance and energy efficiency of multicore processors [ISCA'16].
Python-Based Frameworks to Enable a Vertically Integrated Research Methodology

As technology trends force architects to consider greater heterogeneity and hardware specialization, an increasing emphasis on vertically integrated computer architecture methodologies is needed to effectively assess performance, area, and energy metrics of future architectures. However, constructing such a methodology with existing tools is a significant challenge due to the unique languages, tools, and design patterns used in functional-level (FL), cycle-level (CL), and register-transfer-level (RTL) modeling. We are developing a new Python-based framework called PyMTL that aims to close this computer architecture research methodology gap by providing a unified design environment for FL, CL, and RTL modeling. Our framework leverages the Python programming language to create a highly productive embedded domain-specific-language for concurrent-structural modeling and hardware design. While the use of Python as a modeling and framework implementation language provides considerable benefits in terms of productivity, it comes at the cost of significantly longer execution times resulting in a performance-productivity gap. To close this gap, we have developed new just-in-time compilation techniques to mitigate this performance-productivity gap [MICRO'14,DAC'18]. We have also explored generating fast instruction set simulators (ISSs) from simple Python-based architecture descriptions with meta-tracing JIT compilers [ISPASS'15], and then embedding these fast ISSs in standard C++ simulators to enable fast, accurate, and agile simulation [ISPASS'16]. Both PyMTL and Pydgin are open-source projects under active development:
FPGA/ASIC Prototyping
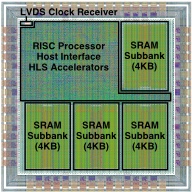
Building prototype systems is an integral part of our research, as this is one of the best ways to validate assumptions, gain intuition about physical design issues, and provide platforms for future software research. We have developed a simple FPGA prototype of our XLOOPS architecture using the Zedboard, which includes a Zynq-7000 All Programmable SoC. The specific XLOOPS microarchitecture mapped to the FPGA included a pipelined RISC general-purpose processor, four-lane loop-pattern specialization unit (LPSU), 16KB instruction/data cache, and support for the unordered concurrent loop pattern. In 2016, we taped out our first computer architecture ASIC test chip on an IBM 130nm process. The 2x2mm 1.3M-transistor chip was designed and implemented using our new PyMTL hardware modeling framework and includes a simple pipelined 32-bit RISC processor, custom LVDS clock receiver, 16KB of on-chip SRAM, and application-specific accelerators generated using commercial C-to-RTL high-level synthesis tools [HOTCHIPS'16 poster]. In 2017, we taped out the Celerity system-on-chip: a 5x5mm 385M-transistor chip in TSMC 16nm designed and implemented by a large team of over 20 students and faculty from UC San Diego, University of Michigan, and Cornell as part of the DARPA Circuit Realization At Faster Timescales (CRAFT) program. The chip included a fully synthesizable PLL, digital LDO, five modified Chisel-generated RISC-V Rocket cores, a 496-core RISC-V tiled manycore processor, tightly integrated Rocket-to-manycore communication channels, complex HLS-generated BNN (binarized neural network) accelerator, manycore-to-BNN high-speed links, sleep-mode 10-core manycore, top-level bus interconnect, high-speed source-synchronous off-chip I/O, and a custom flip-chip package. Cornell led the Rocket+BNN accelerator logical/physical design and also made key contributions to the top-level logical/physical integration and design/verification methodology [HOTCHIPS'17,IEEEMICRO'18, CARRV'17].
Previous Research Projects
Chip-Level Nanophotonic Interconnection Networks

Although we can expect tens to hundreds of cores on a die within this decade, corresponding increases in communication bandwidth and energy efficiency are also required to improve overall application performance. Our colleagues at MIT and Cornell developed novel monolithic silicon-photonic devices that can potentially provide immense bandwidth density at low energy and low cost. We investigated how to leverage this technology to implement manycore processor-to-DRAM networks [IEEE-MICRO'09], low-diameter non-blocking networks for global on-chip communication [NOCS'09], and DRAM memory channels [ISCA'10]; and we developed design guidelines for building future networks [JETCAS'12,Springer'13]. I organized a Workshop on the Interaction between Nanophotonic Devices and Systems at MICRO-42 to help bring together device-level and system-level researchers to talk about their work and to share their experiences with this emerging technology [WINDS'10].
Vector-Thread Architectures

Vector-threading (VT) is a new architectural design pattern that attempts to combine the efficiency of vector architectures with the flexibility of multithreaded execution [ISCA'04,MICRO'04]. The VT pattern includes a control thread that manages its own array of microthreads. The control thread uses vector memory instructions to efficiently move data and vector fetch instructions to broadcast scalar instructions to all microthreads, which are then executed in lockstep. These vector mechanisms are complemented by the ability for each microthread to direct its own control flow. To help validate our initial ideas we designed and fabricated the Scale VT Processor, a prototype for embedded applications implemented in a TSMC 0.18um process [TODAES'08]. Scale includes a RISC control processor and a four-lane vector unit that can execute 16 operations per cycle and supports up to 128 active threads. The 16 sq mm chip runs at 260 MHz while consuming 0.4–1.1 W across a range of kernels. This early VT work was selected as an IEEE Micro Top Pick in 2004 and a DAC/ISSCC Student Design Contest Winner in 2007. Our later work studied techniques for simplifying VT architectures through a unified control-/micro-thread instruction set, a microarchitecture based on minimal changes to a standard vector-SIMD implementation, and an explicitly data-parallel C++ programming methodology [ISCA'11,TOCS'13].
Synthetic Biology

Synthetic biology studies how to build artificial biological systems for engineering applications using classic engineering techniques such as abstraction, modeling, simulation, incremental testing, and modular design. My interest in this field developed from participating in the very first iGEM competition in 2004. Our team attempted to build synchronized chemotactic oscillators [iGEM-Proposal'04,iGEM-Presentation'04], and during the summer I did some preliminary work on modeling a Lux/AiiA relaxation oscillator [Personal-Memo'04]. Those experiences motivated a study on using zinc-finger and leucine-zipper protein domains to create scalable cellular logic technologies [NSC'04]. I continued to follow the field and worked with colleagues at UC Berkeley on efficient algorithms for the assembly of standard biological parts [NAR'10].