On-going projects
These are active projects, please come back later for more information...
Combine software and hardware to control information flow and verify security
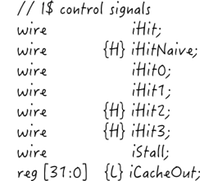
Information flow control is a promising method for building future applications and computing
systems with strong security. However, information flows, especially timing channel leakage, are
extremely difficult to control using pure software approaches, because the timing behavior of
a program relies on the underlying hardware.
In this project, we are trying to combine software and hardware approaches to provide strong information
flow control. In the software level, we add annotations to the program to track information flow. These
annotations are then communicated to the hardware which enforces the information flow control through
its implementation. To verify the security of the implemented hardware, we extended Verilog with
annotations that support comprehensive, precise reasoning about information flows at the hardware level...
Full System Timing Channel Protection
With the emergence of new computing platform such as cloud computing, hardware resources
are extensively shared among processes, programs and users. The dynamic sharing of hardware
resources introduces interference between different security domains, which becomes a vector
for timing channels. Any hardware resources that are shared among different security domains
have the risk of timing channel attacks. These hardware resources includes but not limited to
core pipelines, branch predictors, caches, on-chip network, and memory.
In this project, we are working on efficient scheme to provide full system
protection against timing channels in shared hardware resources throughout the system...
Past projects
Timing Channel Protection for a Shared Memory Controller (HPCA14')
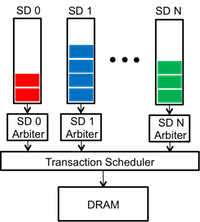
Modern computing systems are increasingly vulnerable to timing channel attacks due
to interference through extensive hardware resource sharing between programs, threads
and virtual machines. Previous research proposed some hardware techniques to deal with
timing channels through hardware resources such as cache, on-chip network. However, no
hardware techniques have looked into the timing channel through a shared memory controller.
In this project, we demonstrated the existence of timing channels through a shared memory
controller. Our solution, Temporal Partitioning solves this problem using several
methods:
- Per Security Domain (SD) based queuing structure
- Time Division Multiplexing (TDM) based scheduling algorithm
- Dead time to drain in-flight transactions
Energy-Efficient Task Mapping Algorithm for Many-Core Processors (NOCS13')

Many-core platforms with an on-chip interconnect network, sometimes referred to as Network-on-Chip (NoC), have emerged as a likely candidate for future microprocessor architecture. In order to efficiently utilize the large number of cores, however, application tasks need to be carefully mapped to processing cores (network nodes). In this project, we propose to apply a heuristic approach for VLSI layout called Quadrisection to the task mapping problem for a two-dimensional on-chip network such as meshes.
Efficient Timing Channel Protection for On-Chipe Networks (NOCS12')
On-chip network is often dynamically shared among applications that are concurrently
running on a chip- multiprocessor (CMP). In general, such shared resources imply that
applications can affect each other’s timing characteristics through interference in shared
resources. For example, in on-chip networks, multiple flows can compete for links and buffers.
We show that this interference is an attack vector through which a malicious application may
be able to infer data-dependent information about other applications (side channel attacks),
or two applications can exchange information covertly when direct communications are prohibited
(covert channel attacks).
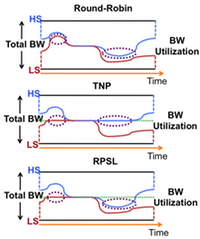
To prevent these timing channel attacks, approaches such as Spatial
Network Partitioning (SNP) or Temporal Network Partitioning (TNP) can be used, but they are
very inefficient in bandwidth utilization. We propose an efficient scheme, called
Reversed Priority with Static Limits (RPSL)
which exploits one-way timing channel protection from high security level to low security level by:
- Giving high priority to packets from low security level in router arbitration
- Setting a static limit on bandwidth utilization for low security level
Routing Algorithm to Reduce Static Power of On-Chip Networks
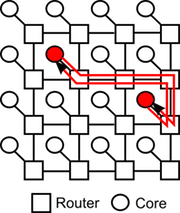
Technology scaling indicates that future microprocessors will be power limited. Since microprocessors
will be power limited and only a portion of the silicon can be turned on, recent studies have proposed
specialized and adaptive cores for future multi-core systems. However, the on-chip networks for these
systems have been designed assuming that all nodes are simultaneously active.
In this project, we investigate
activating only a subset of routers in the network. Specifically, we propose an oblivious routing
algorithm, called "BackTrack", to maximize the number of unused routers which can then be turned off to save static power.
The basic idea is to have flows in both directions between each pair of network nodes use the same set of routers.
We proved this routing algorithm to be deadlock-free, and we show that this routing algorithm can reduce
power usage with little to no performance degradation on the network.
Performance Evaluation of On-Chip Sensor Network (SENoC) in MPSoC

As technology scaling, more processing units (PUs) are integrated in multiprocessor system-on-chip (MPSoC)
to achieve higher performance. Due to the higher variations resulted from reducing feature sizes and the
needs of lower power consumption, on-chip monitoring of environmental information, such as thermal, voltage,
and frequency, is becoming increasingly important. To address this need, sensors are integrated into
network-on-chip (NoC) to perform system monitoring. However, sensors which transfer their data through NOC
will compete with PUs for the limited bandwidth resources, thus communication between PUs will be delayed.
To evaluate the sensors' overhead on the regular data traffic, we implement a VC based NoC. The sensor data
are transferred through NoC together with the regular data. We study the average delay of regular data and
sensor data, respectively. We compare the experimental results with that of a NOC without sensors. The results
show that the overhead of sensors is negligible.