XLOOPS: Explicit Loops Specialization
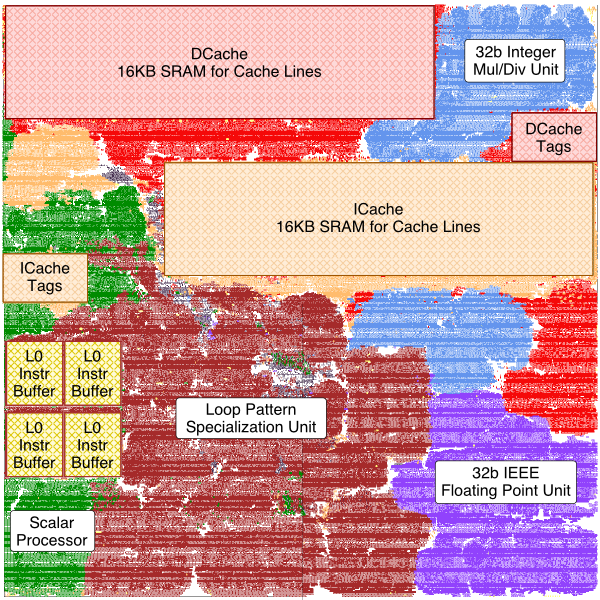
We have developed a new approach to programmable accelerators called explicit loop specialization (XLOOPS) which is based on the idea of explicitly encoding inter-iteration loop dependence patterns in the instruction set to enable exploiting fine-grain loop-level parallelism [MICRO'14]. The above figure is a post-place-and-route chip plot that illustrates a specific XLOOPS microarchitecture with a simple pipelined RISC general-purpose processor, four-lane loop-pattern specialization unit (LPSU), 16KB instruction/data cache, and support for the unordered concurrent loop pattern. We used an automated Synopsys-based ASIC CAD toolflow to generate and analyze this design in order to improve the credibility of our area, energy, and performance estimates.