Fine-Grain Hardware Worklists for GPGPUs
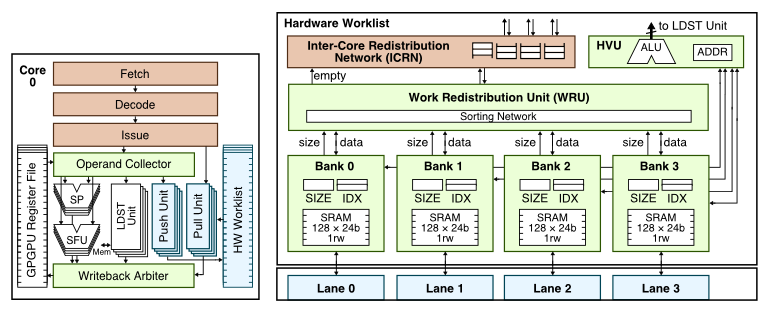
These diagrams illustrate our technique for integrating fine-grain hardware worklists into a GPGPU to accelerate execute irregular algorithms that read and modify graph-based data structures and dynamically generate additional parallelism [MICRO'14]. The diagram on the left shows how we modify the baseline GPGPU pipeline to support accessing the hardware worklist. The figure on the right shows in more detail the interface between the GPGPU lanes and the hardware worklist (HWWL). The lanes access the distributed HWWL banks which are managed by the work redistribution unit (WRU). The HWWL virtualization unit (HVU) handles reads/writes with the overflow buffer. The inter-core redistribution network (ICRN) is a simple tree network that facilitates work distribution between cores.